Selected Publications
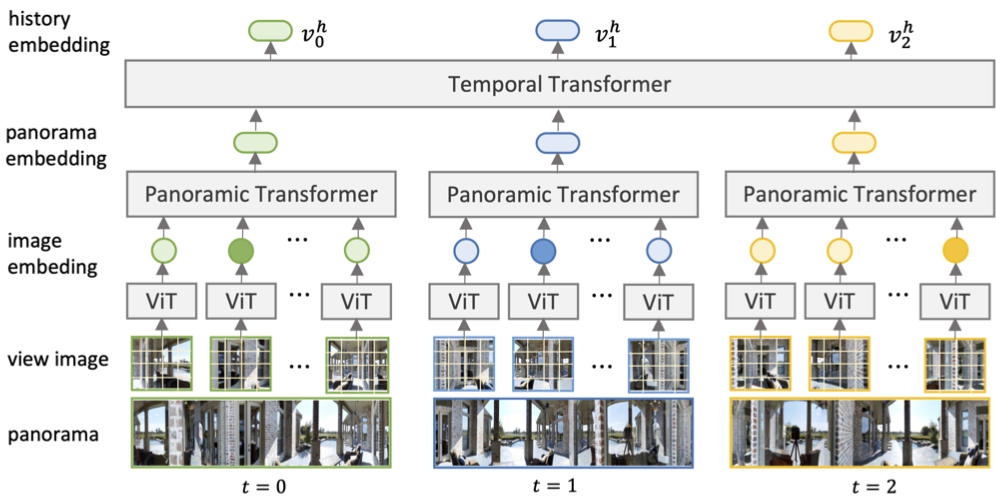
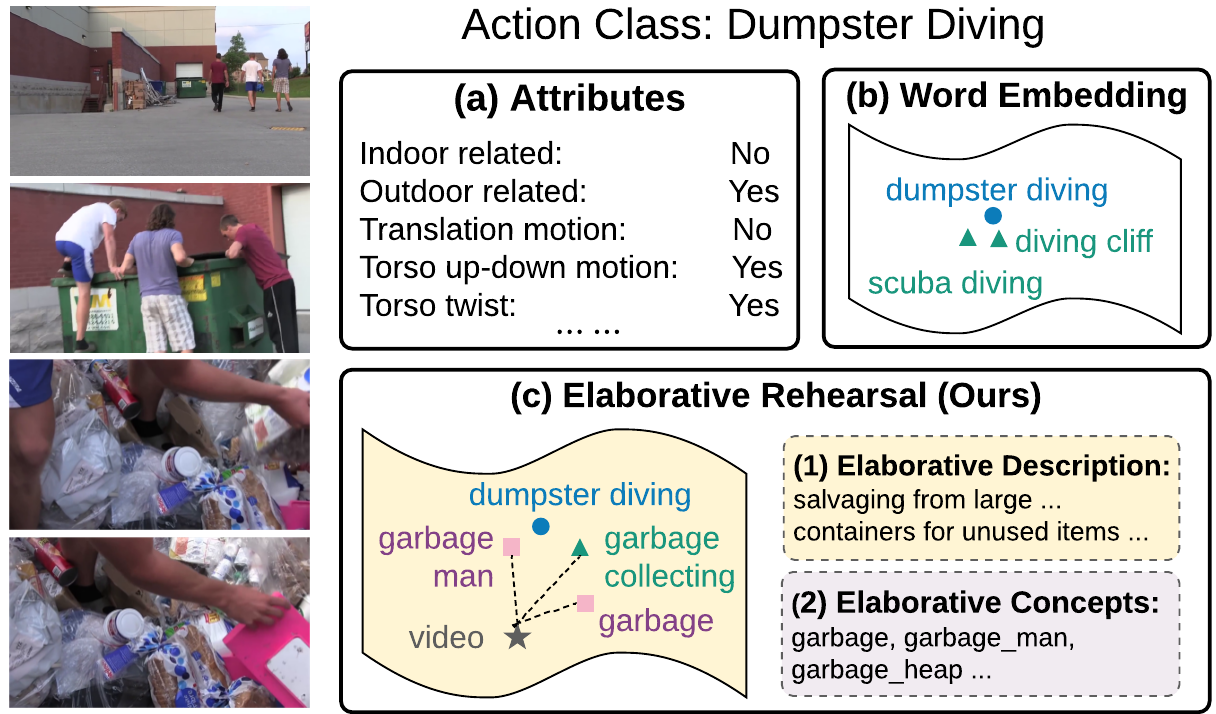


Question-controlled Text-aware Image Captioning
Anwen Hu, Shizhe Chen, Qin Jin.ACM Multimedia, 2021. [PDF]

Product-oriented Machine Translation with Cross-modal Cross-lingual Pre-training
Yuqing Song, Shizhe Chen, Qin Jin, Wei Luo, Jun Xie, Fei Huang.ACM Multimedia, 2021 (Oral). [PDF]
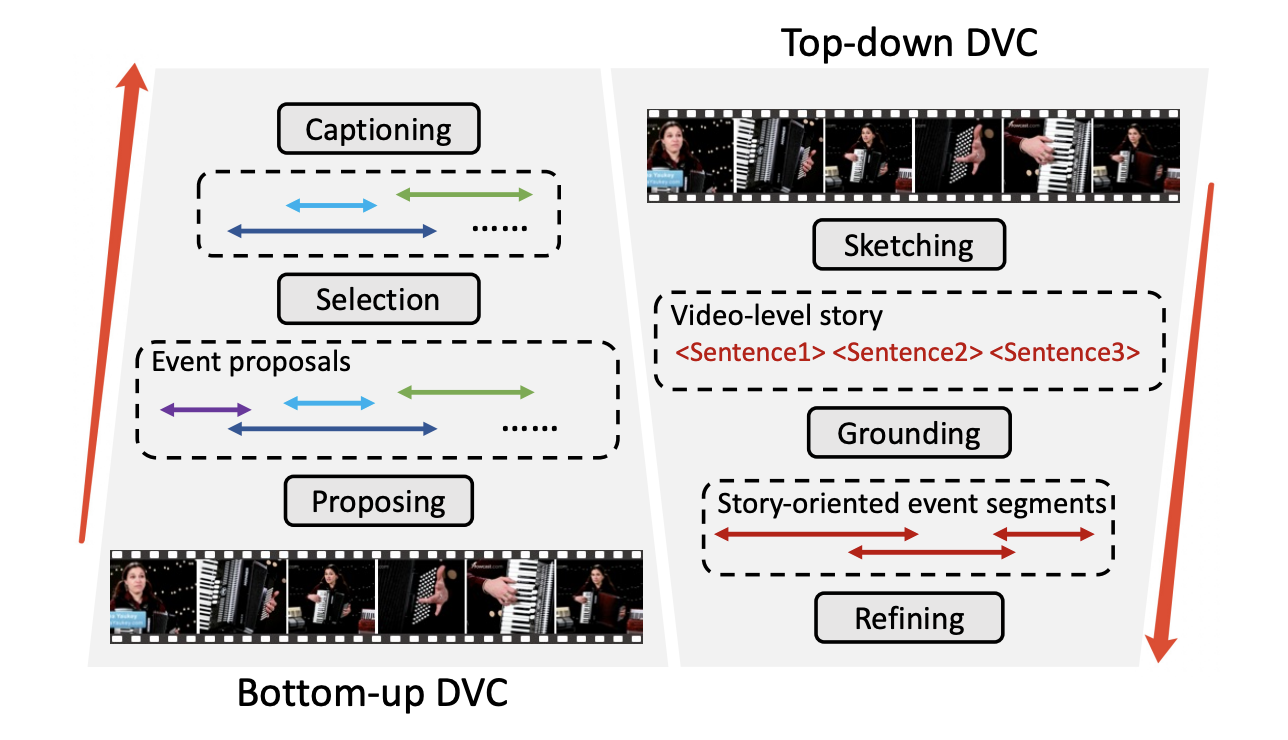
Sketch, Ground, and Refine: Top-Down Dense Video Captioning
Chaorui Deng, Shizhe Chen, Da Chen, Yuan He, Qi Wu.CVPR, 2021 (Oral). [PDF]
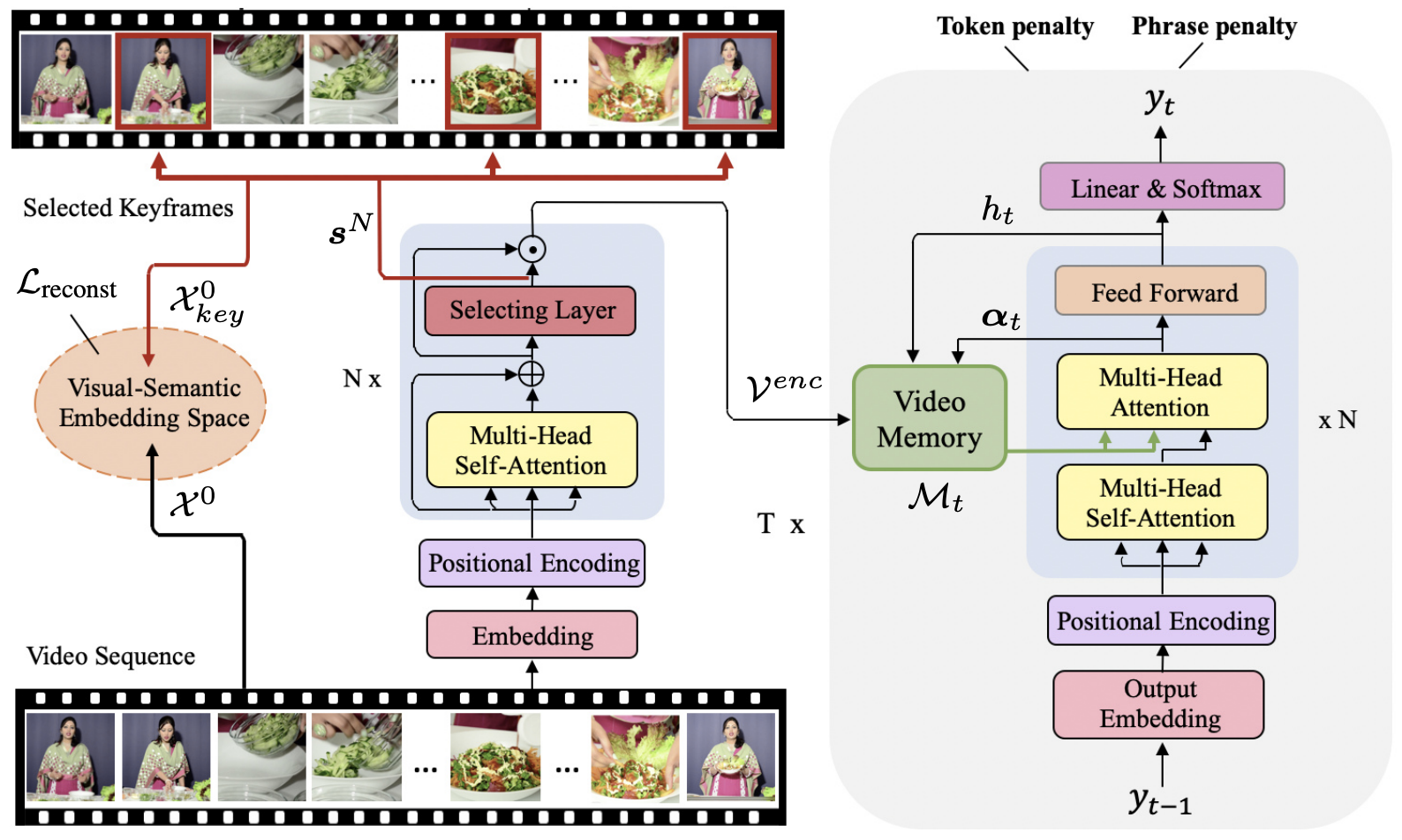
Towards Diverse Paragraph Captioning for Untrimmed Videos
Yuqing Song, Shizhe Chen, Qin Jin.CVPR, 2021. [PDF]
From words to sentence: A progressive learning approach for zero-resource machine translation with visual pivots
Shizhe Chen, Qin Jin, Jianlong FuIJCAI, 2019. [PDF]
Unsupervised Bilingual Lexicon Induction from Mono-lingual Multimodal Data
Shizhe Chen, Qin Jin, Alexander HauptmannAAAI, 2019. [PDF]
Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards
Yuqing Song, Shizhe Chen, Qin JinACM Multimedia, 2019 (Oral). [PDF]
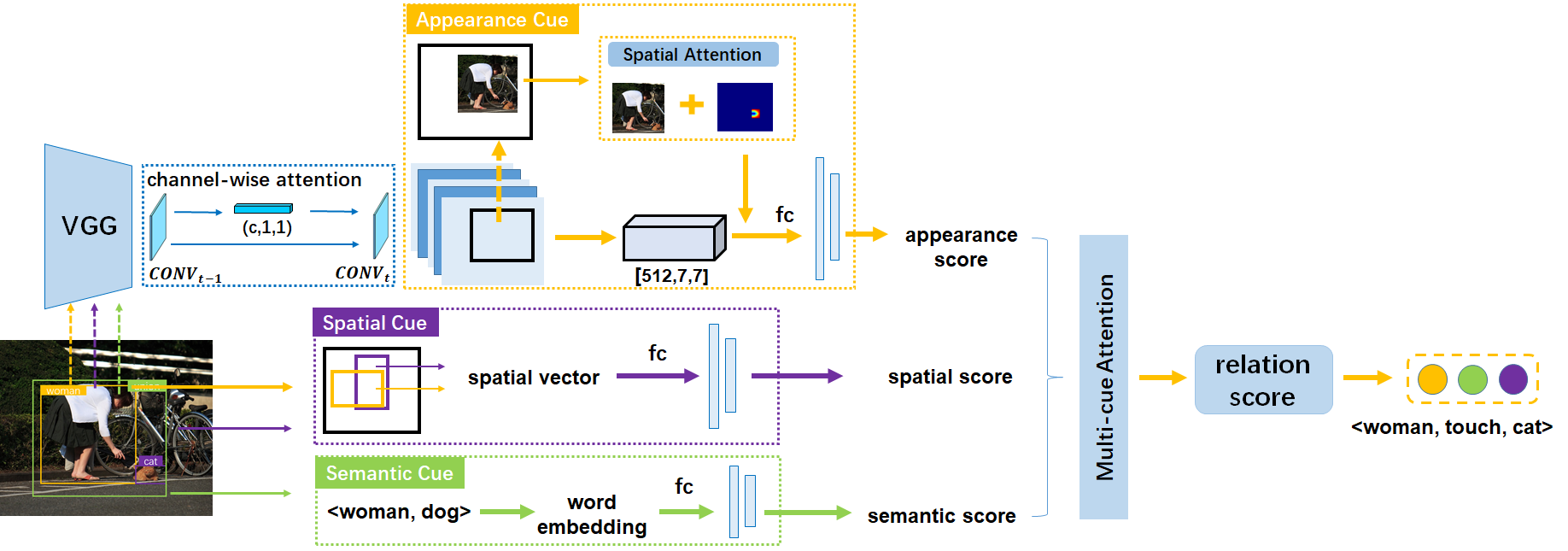
Visual Relation Detection with Multi-Level Attention
Sipeng Zheng, Shizhe Chen, Qin JinACM Multimedia, 2019. [PDF]

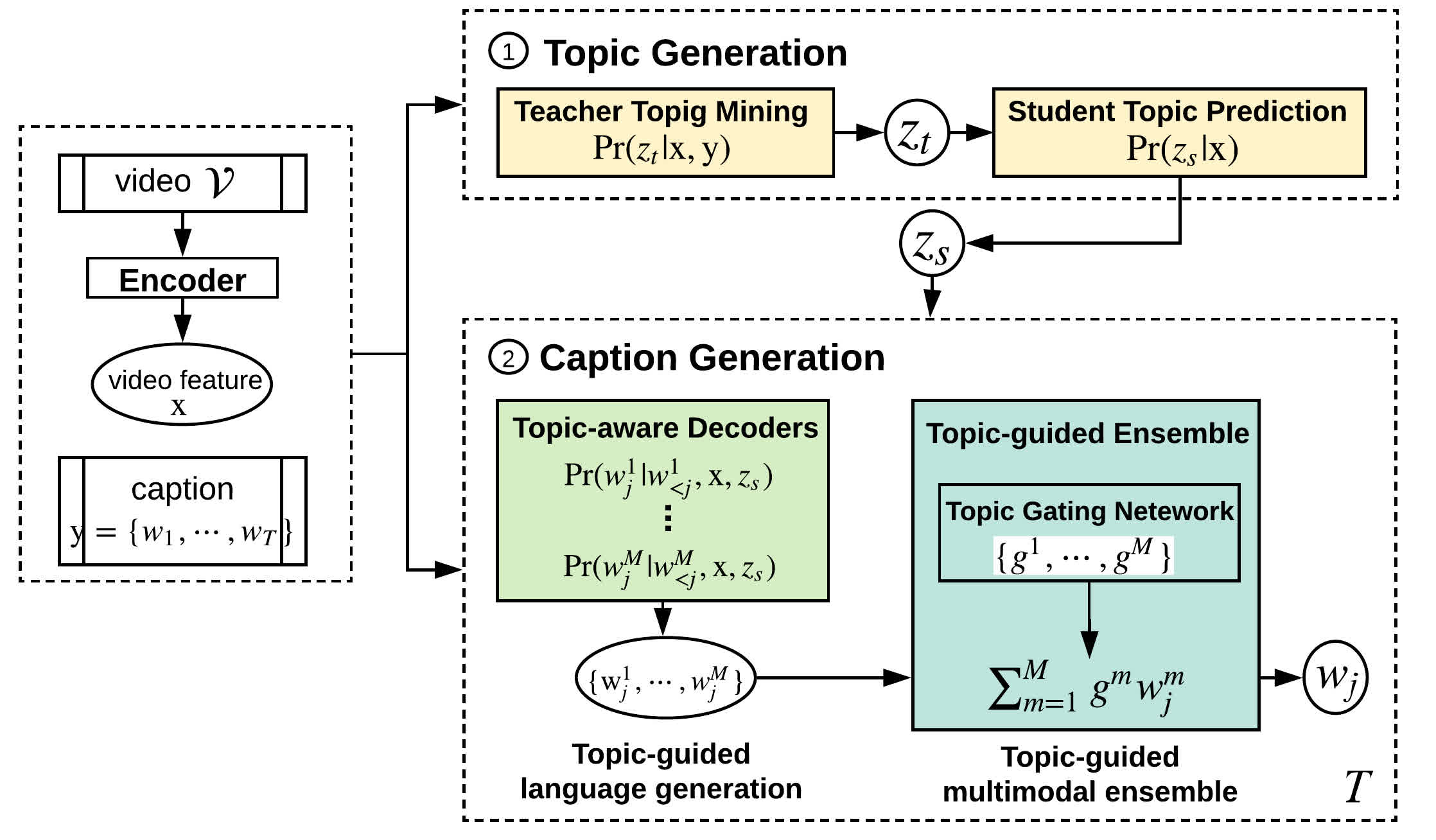
Generating Video Descriptions with Latent Topic Guidance
Shizhe Chen, Qin Jin, Jia Chen, Alexander HauptmanTMM, 2019. [PDF]

Class-aware Self-attention for Audio Event Recognition
Shizhe Chen, Jia Chen, Qin Jin, Alexander HauptmanICMR, 2018 (Best Paper Runner-up). [PDF]
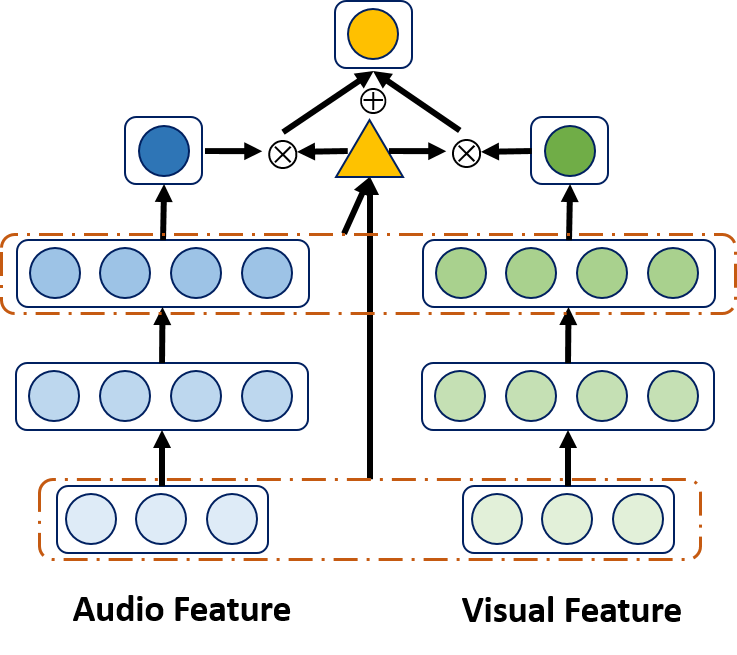
Multi-modal Conditional Attention Fusion for Dimensional Emotion Prediction
Shizhe Chen, Qin JinACM Multimedia, 2016. [PDF]