History Aware Multimodal Transformer for Vision-and-Language Navigation
|
|
|
|
|
|
|
|
|
Abstract
Vision-and-language navigation (VLN) aims to build autonomous visual agents that follow instructions and navigate in real scenes. To remember previously visited locations and actions taken, most approaches to VLN implement memory using recurrent states. Instead, we introduce a History Aware Multimodal Transformer (HAMT) to incorporate a long-horizon history into multimodal decision making. HAMT efficiently encodes all the past panoramic observations via a hierarchical vision transformer (ViT), which first encodes individual images with ViT, then models spatial relation between images in a panoramic observation and finally takes into account temporal relation between panoramas in the history. It, then, jointly combines text, history and current observation to predict the next action. We first train HAMT end-to-end using several proxy tasks including single step action prediction and spatial relation prediction, and then use reinforcement learning to further improve the navigation policy. HAMT achieves new state of the art on a broad range of VLN tasks, including VLN with fine-grained instructions (R2R, RxR), high-level instructions (R2R-Last, REVERIE), dialogs (CVDN) as well as long-horizon VLN (R4R, R2R-Back). We demonstrate HAMT to be particularly effective for navigation tasks with longer trajectories.
Method
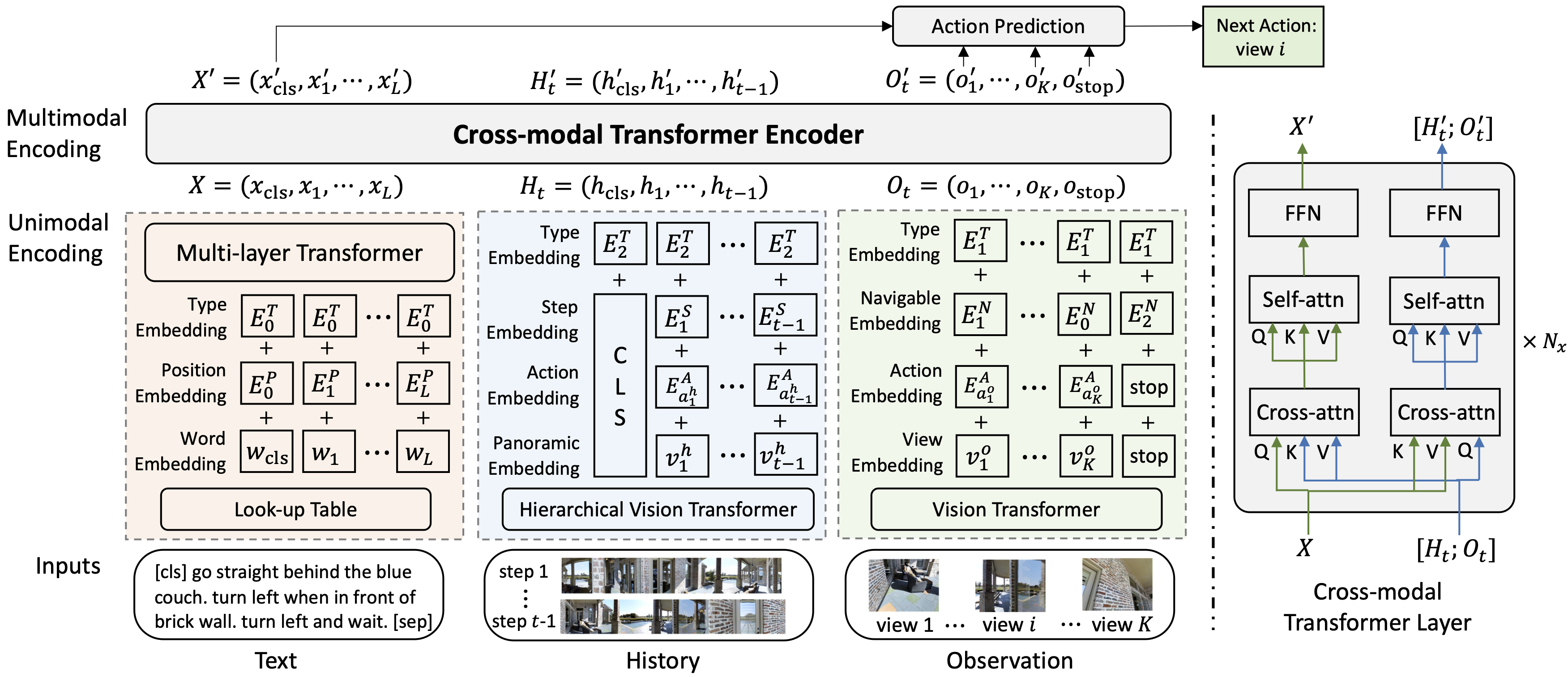
The overall architecture of History Aware Multimodal Tranformer (HAMT). HAMT jointly encodes textual instruction, full history of previous observations and actions, and current observation to predict the next action.
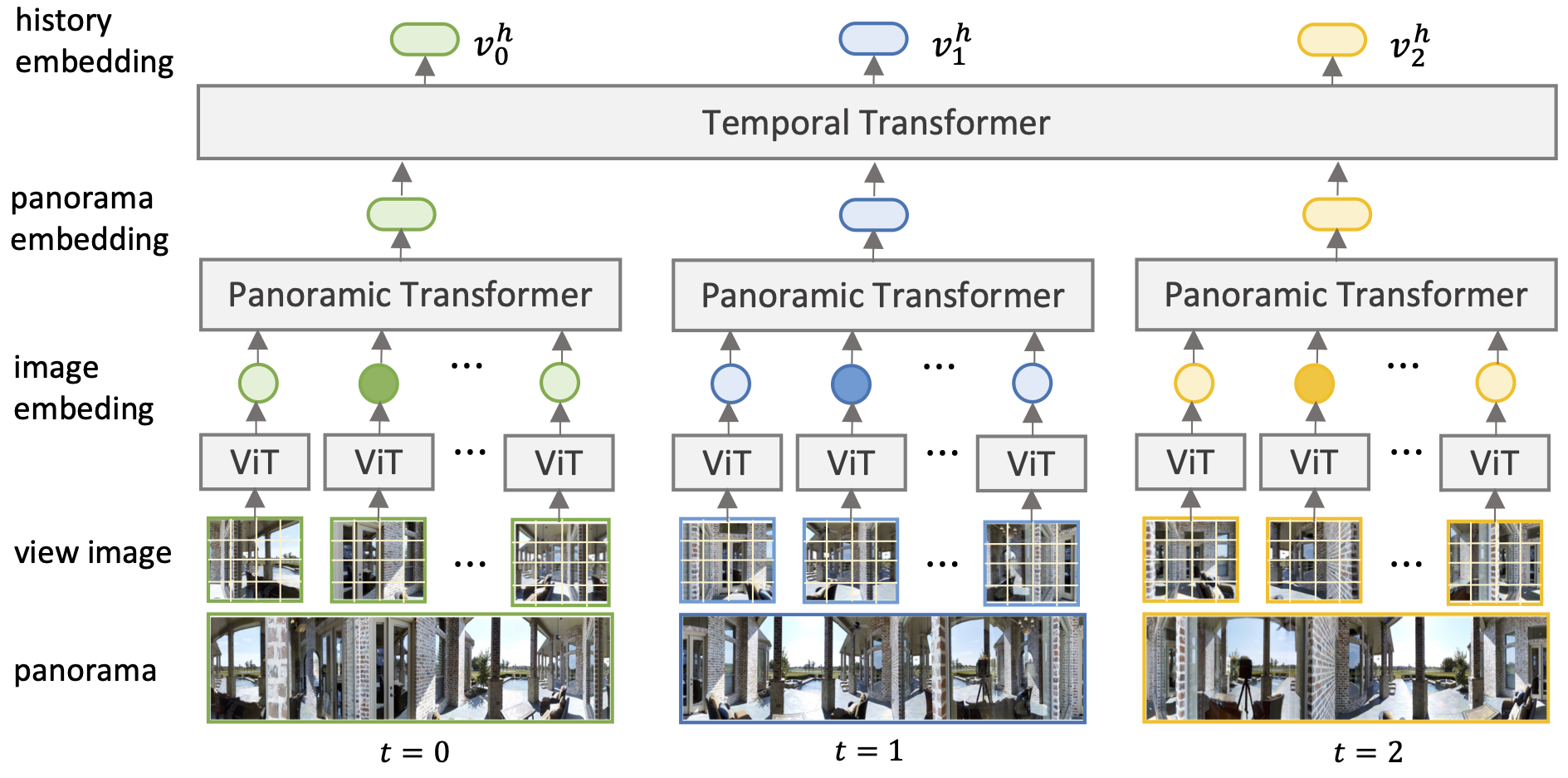
Hierarchical history encoding. It first encodes individual view images with ViT, then models the spatial relation between images in each panorama, and finally captures the temporal relation between panoramas in the history.
Talk
BibTeX
@InProceedings{chen2021hamt,
author = {Chen, Shizhe and Guhur, Pierre-Louis and Schmid, Cordelia and Laptev, Ivan},
title = {History Aware multimodal Transformer for Vision-and-Language Navigation},
booktitle = {NeurIPS},
year = {2021},
}
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 101002 made by GENCI. It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR19-P3IA-0001 (PRAIRIE 3IA Institute) and by Louis Vuitton ENS Chair on Artificial Intelligence.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.