Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
|
|
|
|
|
|
|
|
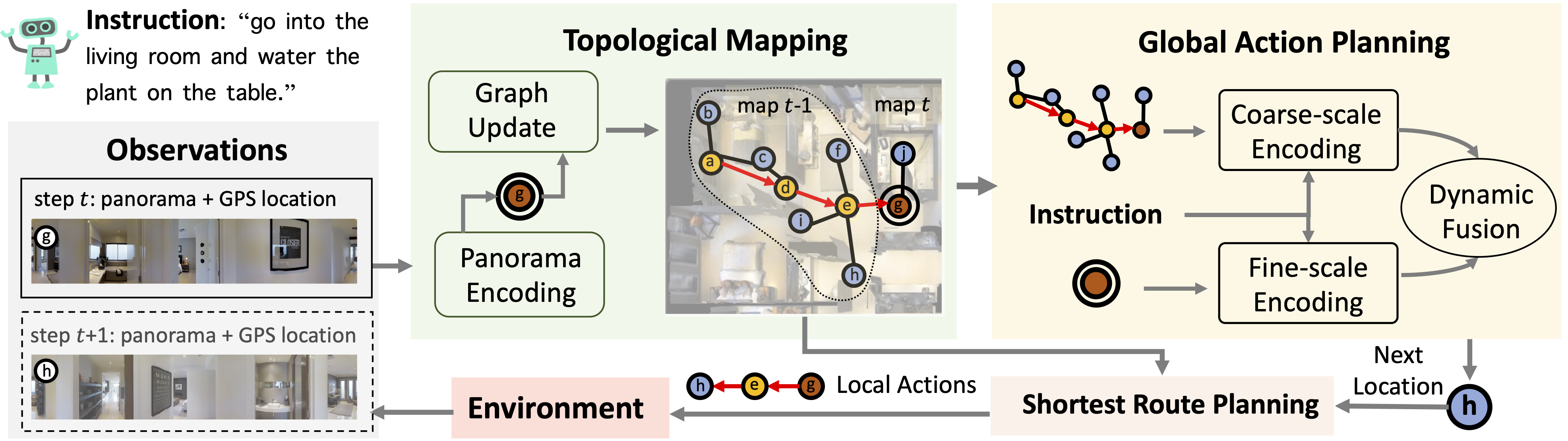
Abstract
Following language instructions to navigate in unseen environments is a challenging problem for autonomous embodied agents. The agent not only needs to ground languages in visual scenes, but also should explore the environment to reach its target. In this work, we propose a dual-scale graph transformer (DUET) for joint long-term action planning and fine-grained cross-modal understanding. We build a topological map on-the-fly to enable efficient exploration in global action space. To balance the complexity of large action space reasoning and fine-grained language grounding, we dynamically combine a fine-scale encoding over local observations and a coarse-scale encoding on a global map via graph transformers. The proposed approach, DUET, significantly outperforms state-of-the-art methods on goal-oriented vision-and-language navigation (VLN) benchmarks REVERIE and SOON. It also improves the success rate on the fine-grained VLN benchmark R2R.
Method
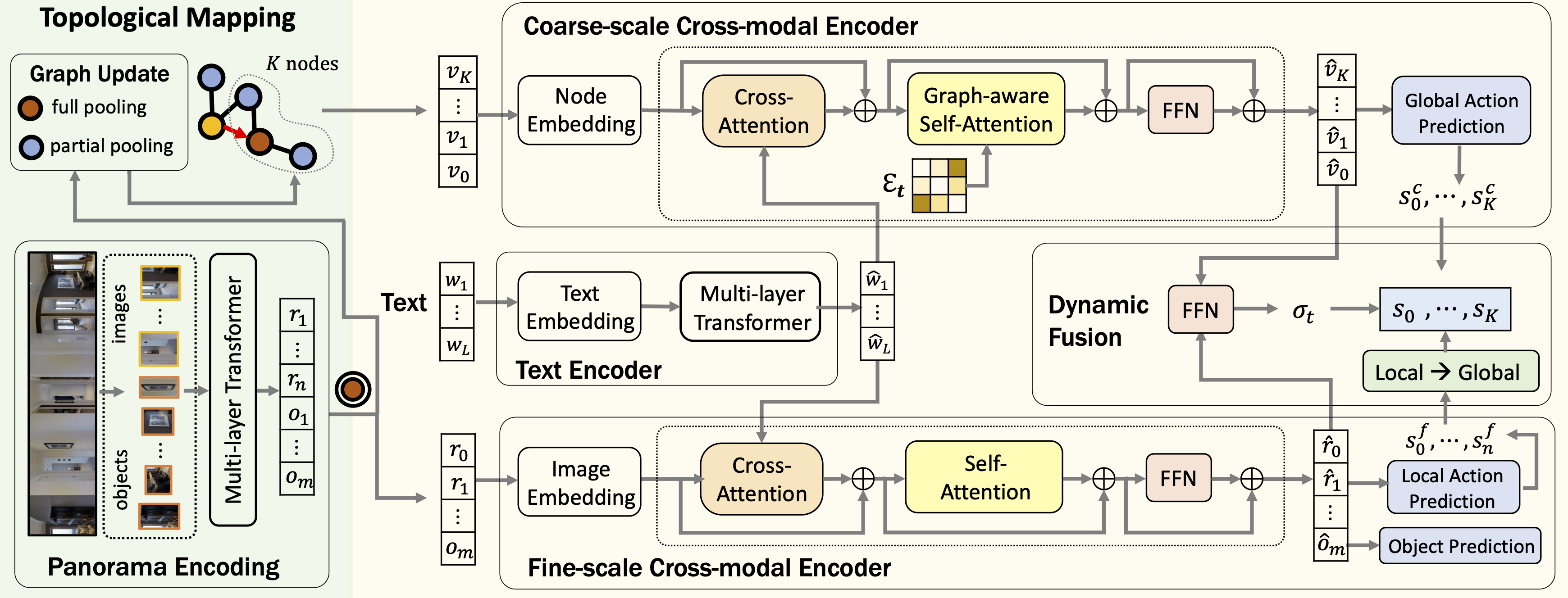
DUET consists of topological mapping (left) and global action planning (right). The mapping module outputs a graph with K node features {v1, ..., vK}, and the current panorama encoding with image features {r1, ..., rn} and object features {o1, ..., om}. Node feature v0 and image feature r0 are used to indicate the 'stop' action. The global action planning uses transformers for coarse- and fine-scale cross-modal encoding and fuses the two scales to obtain a global action score si for each node.
Video: Result Visualization
BibTeX
@InProceedings{Chen_2022_DUET,
author = {Chen, Shizhe and Guhur, Pierre-Louis and Tapaswi, Makarand and Schmid, Cordelia and Laptev, Ivan},
title = {Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation},
booktitle = {CVPR},
year = {2022}
}
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 101002 made by GENCI. It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR19-P3IA-0001 (PRAIRIE 3IA Institute) and by Louis Vuitton ENS Chair on Artificial Intelligence.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.