SUGAR: Pre-training 3D Visual Representations for Robotics
|
|
|
|
|
|
2 Mohamed bin Zayed University of Artificial Intelligence |
Abstract
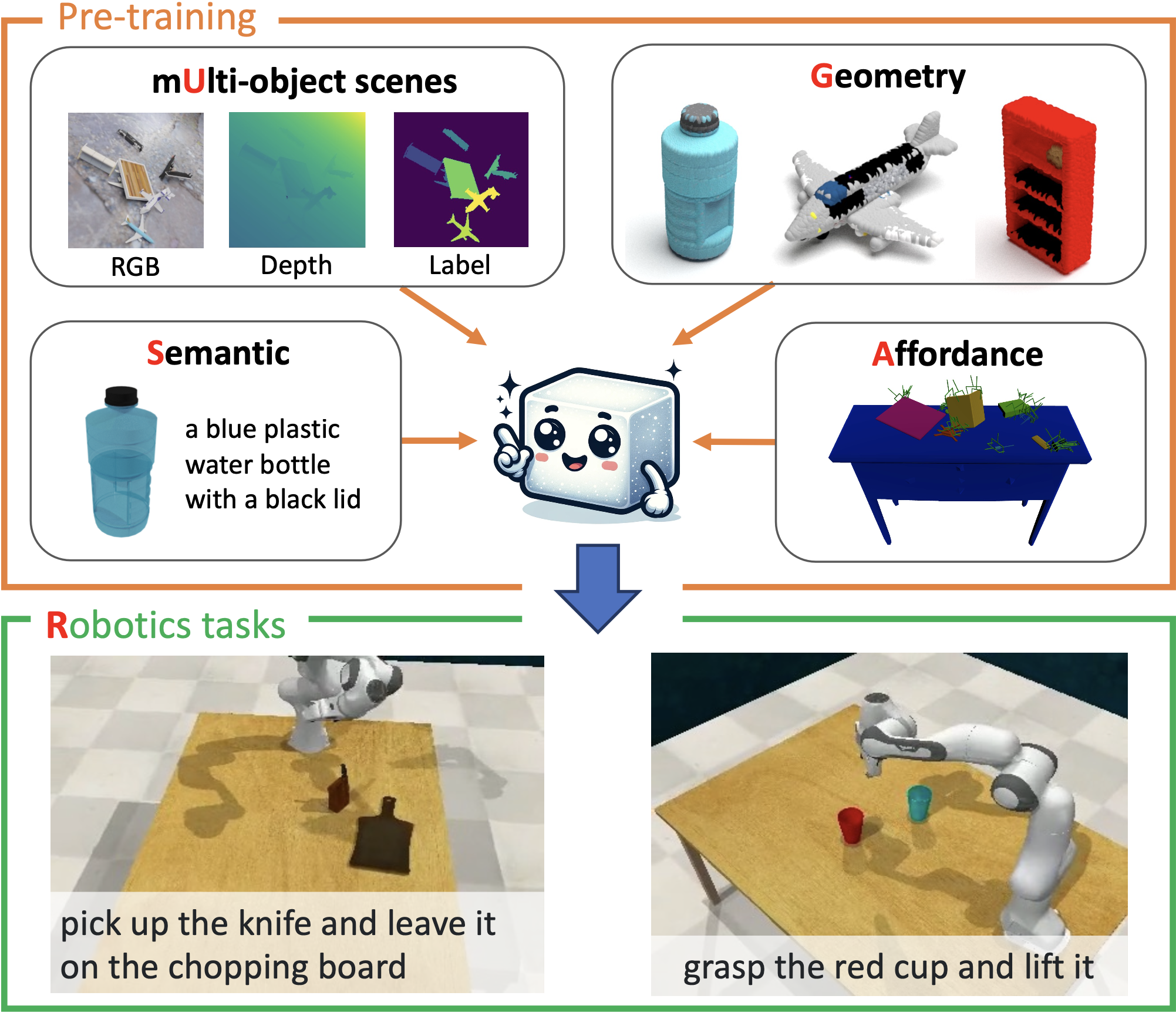
Learning generalizable visual representations from Internet data has yielded promising results for robotics. Yet, prevailing approaches focus on pre-training 2D representations, being sub-optimal to deal with occlusions and accurately localize objects in complex 3D scenes. Meanwhile, 3D representation learning has been limited to single-object understanding. To address these limitations, we introduce a novel 3D pre-training framework for robotics named SUGAR that captures semantic, geometric and affordance properties of objects through 3D point clouds. We underscore the importance of cluttered scenes in 3D representation learning, and automatically construct a multi-object dataset benefiting from cost-free supervision in simulation. SUGAR employs a versatile transformer-based model to jointly address five pre-training tasks, namely cross-modal knowledge distillation for semantic learning, masked point modeling to understand geometry structures, grasping pose synthesis for object affordance, 3D instance segmentation and referring expression grounding to analyze cluttered scenes. We evaluate our learned representation on three robotic-related tasks, namely, zero-shot 3D object recognition, referring expression grounding, and language-driven robotic manipulation. Experimental results show that SUGAR's 3D representation outperforms state-of-the-art 2D and 3D representations.
Method
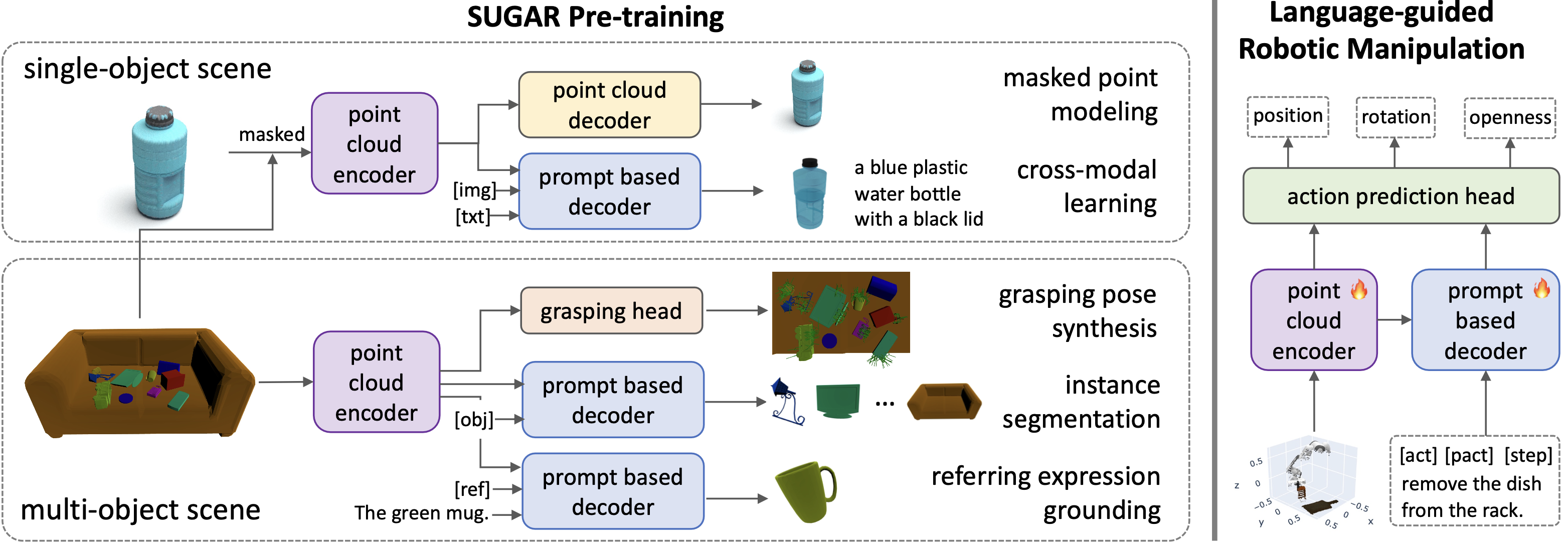
Left: Five pre-training tasks for SUGAR using single- and multi-object scenes. The modules of the same color are shared. Right: The pre-trained point cloud encoder and prompt-based decoder are finetuned on the downstream task of robotic manipulation.
Real Robot Manipulation Results
Hang the red mug.
Put the lemon in the box.
Stack the yellow cup on top of the pink cup.
Put the baseball in the bottom cabinet.
BibTeX
@InProceedings{Chen_2024_SUGAR,
author = {Chen, Shizhe and Garcia, Ricardo and Laptev, Ivan and Schmid, Cordelia},
title = {SUGAR: Pre-training 3D Visual Representations for Robotics},
booktitle = {CVPR},
year = {2024}
}
Acknowledgements
This work was partially supported by the HPC resources from GENCI-IDRIS (Grant 20XX-AD011012122). It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR19-P3IA-0001 (PRAIRIE 3IA Institute), the ANR project VideoPredict (ANR-21-FAI1-0002-01) and by Louis Vuitton ENS Chair on Artificial Intelligence.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.