Gondola: Grounded Vision Language Planning for Generalizable Robotic Manipulation
|
|
|
|
|
|
|
|
|
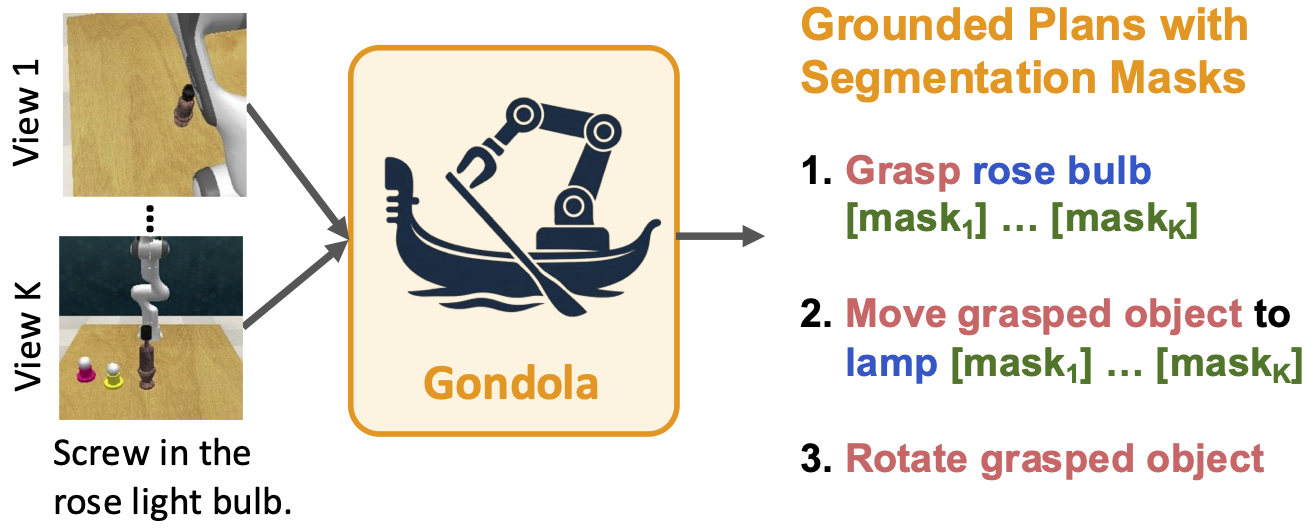
Abstract
Robotic manipulation faces a significant challenge in generalizing across unseen objects, environments and tasks specified by diverse language instructions. To improve generalization capabilities, recent research has incorporated large language models (LLMs) for planning and action execution. While promising, these methods often fall short in generating grounded plans in visual environments. Although efforts have been made to perform visual instructional tuning on LLMs for robotic manipulation, existing methods are typically constrained by single-view image input and struggle with precise object grounding. In this work, we introduce Gondola, a novel grounded vision-language planning model based on LLMs for generalizable robotic manipulation. Gondola takes multi-view images and history plans to produce the next action plan with interleaved texts and segmentation masks of target objects and locations. To support the training of Gondola, we construct three types of datasets using the RLBench simulator, namely robot grounded planning, multi-view referring expression and pseudo long-horizon task datasets. Gondola outperforms the state-of-the-art LLM-based method across all four generalization levels of the GemBench dataset, including novel placements, rigid objects, articulated objects and long-horizon tasks.
Method
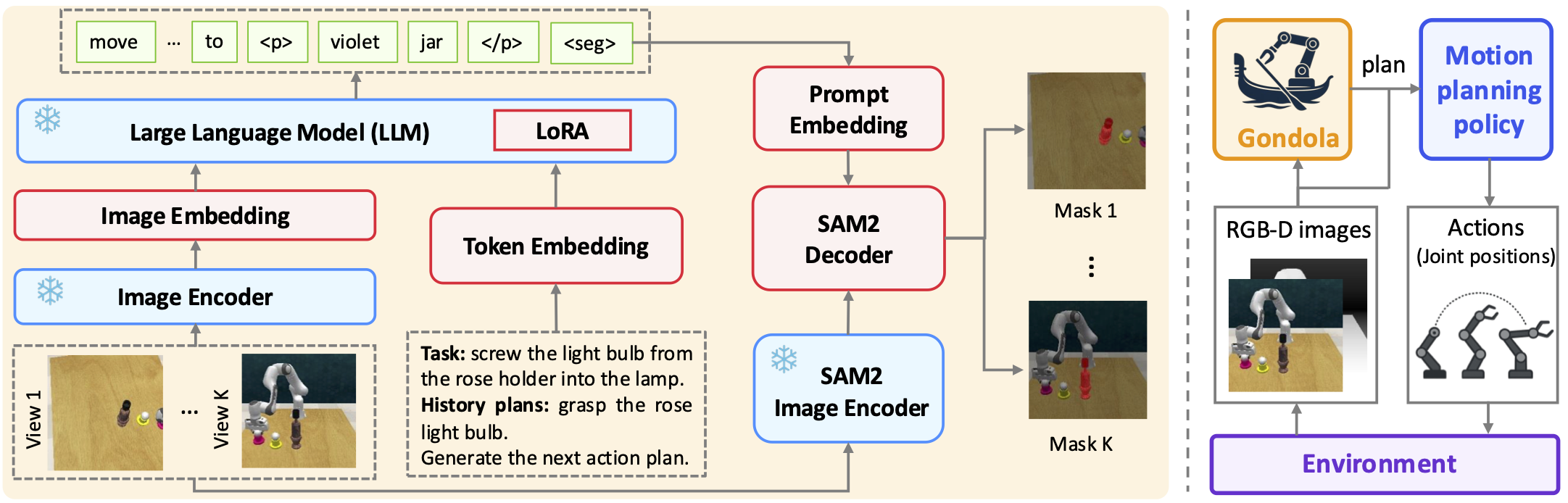
Left: Gondola model architecture, consisting of a shared visual encoder for multi-view images, an LLM to generate action and object names along with segmentation tokens, and SAM2 to decode masks.
Right: Integrating Gondola with a motion planning policy for task execution.
BibTeX
@inproceedings{Chen_2026_Gondola,
author = {Chen, Shizhe and Garcia, Ricardo and Pacaud, Paul and Schmid, Cordelia},
title = {Gondola: Grounded Vision Language Planning for Generalizable Robotic Manipulation},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2026}
}
Acknowledgements
This work was partially supported by the HPC resources from GENCI-IDRIS (Grant 20XX-AD011012122 and AD011014846). It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “France 2030" program, reference ANR-23-IACL-0008 (PR[AI]RIE-PSAI projet), the ANR project VideoPredict (ANR-21-FAI1-0002-01), and the Paris Île-de-France Région in the frame of the DIM AI4IDF.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.