PointACT: Vision-Language-Action Models with Multi-Scale Point-Action Interaction
|
|
|
|
|
|
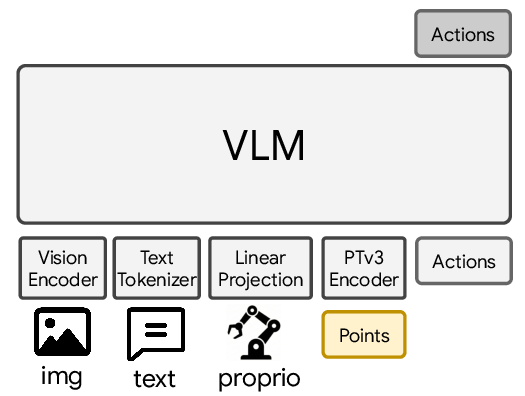
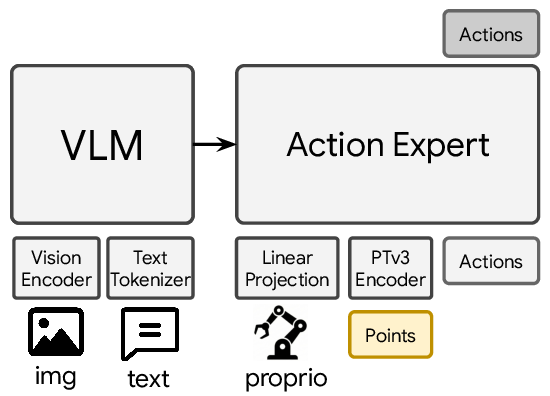
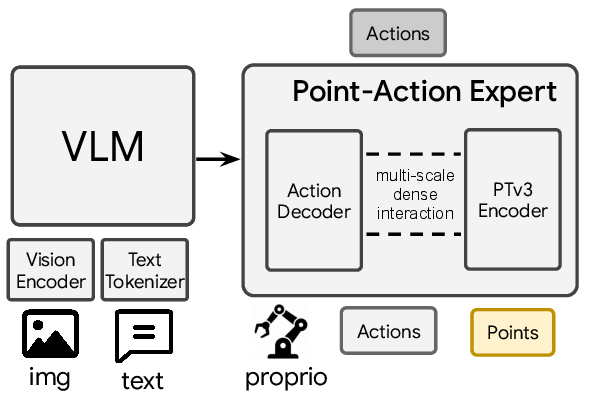
Comparison of 3D integration strategies in VLAs. (a) Monolithic 3D-aware VLA: 3D point features are fed directly into the pretrained VLM backbone, which largely increases the computation burden and may disrupt pretrained representations. (b) Dual-system 3D-aware VLA: 3D information is introduced into a separate action expert, but typically through coarse-grained global features with limited interaction between geometry and actions. (c) PointACT (ours): a dedicated point–action expert enables fine-grained, multi-scale interaction between point cloud features and action tokens during decoding, preserving the pretrained VLM while allowing geometry to directly shape action generation.
Abstract
Vision-Language-Action (VLA) models have shown strong potential for general-purpose robotic manipulation by leveraging large pretrained vision-language backbones. However, most existing VLAs rely primarily on 2D visual representations, which limit their ability to reason about fine-grained geometry and spatial grounding - capabilities that are essential for precise and robust manipulation in 3D environments. In this paper, we propose PointACT, a dual-system 3D-aware VLA policy that integrates hierarchical 3D point cloud representations directly into the action decoding process. PointACT employs a multi-scale point-action interaction mechanism with efficient bottleneck window self-attention, enabling evolving action tokens to densely attend to both local geometric detail and global scene structure. We evaluate PointACT on the LIBERO and RLBench benchmarks and systematically compare it against monolithic and dual-system VLA baselines, including variants augmented with point cloud inputs. PointACT achieves consistent improvements across both benchmarks, increasing success rates by 10% on the challenging RLBench-10Tasks suite over state-of-the-art pretrained VLAs, with even larger gains when the vision-language backbone is frozen and the action expert is trained from scratch. Extensive ablation studies demonstrate that tightly coupling hierarchical 3D geometry with pretrained 2D semantic representations is critical for robust and spatially grounded robot control. Our results also highlight the promise of pretrained 3D representations for 3D-aware VLA policies.
Method
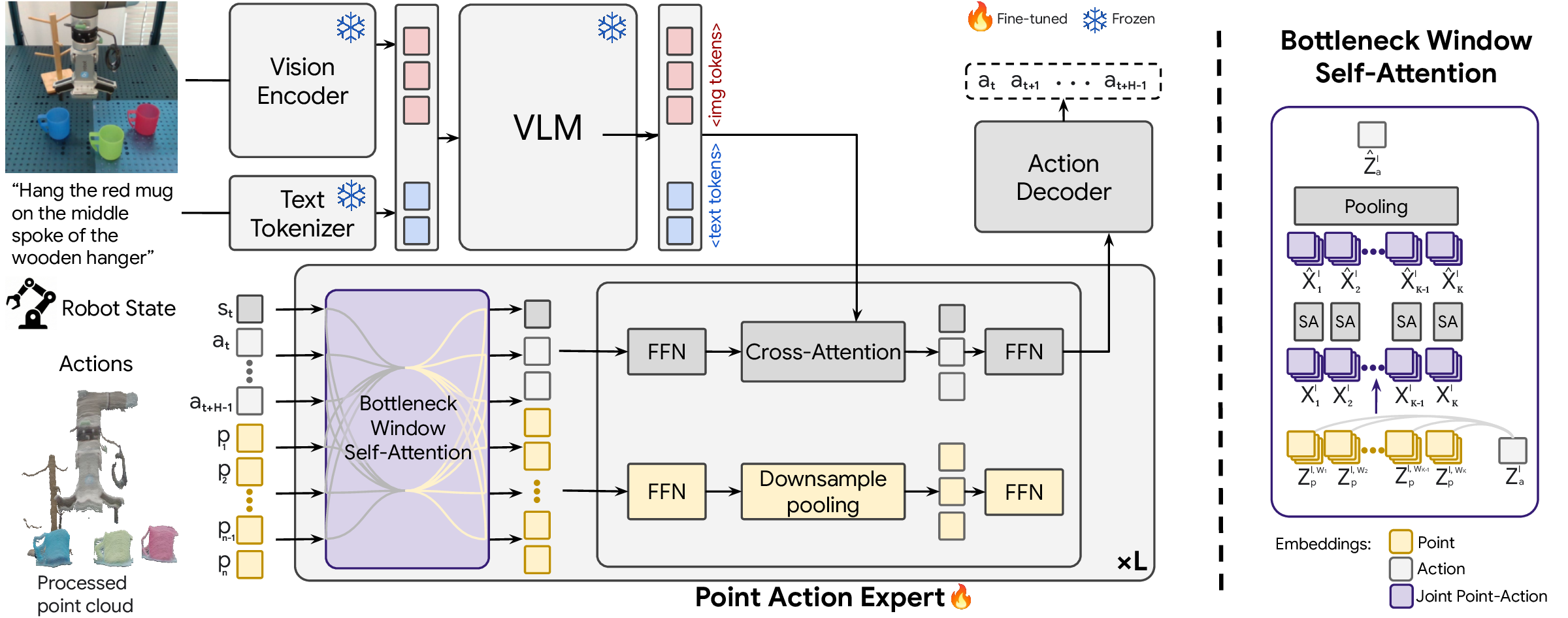
(Left): PointACT Dual-Model Architecture. (Right): Bottleneck Window Self-Attention mechanism. PointACT is a VLA model that equips a frozen pretrained VLM backbone with a point-cloud action expert for geometry-aware control. Language, images, robot state, and 3D point clouds are encoded into tokens, with point clouds producing multi-scale geometric features via a Point Transformer. These point tokens interact with action tokens through multi-scale point–action attention in the action expert, allowing both global structure and local geometry to guide action generation.
BibTeX
@InProceedings{Chen_2026_PointACT,
author = {Chen, Shizhe and Pacaud, Paul and Schmid, Cordelia},
title = {PointACT: Vision-Language-Action Models with Multi-Scale Point-Action Interaction},
booktitle = {Robotics: Science and Systems (RSS)},
year = {2026}
}
Acknowledgements
This work was granted access to HPC resources of IDRIS under the allocation AD011014846 made by GENCI. It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “France 2030” program, reference ANR-23-IACL-0008 (PR[AI]RIE-PSAI projet), the ANR project 3D-GEM (ANR-25-CE23-7777-01), the ANR project VideoPredict (ANR-21-FAI1-0002-01) and the Paris Île-de-France Region in the frame of the DIM AI4IDF. Cordelia Schmid would like to acknowledge the support by the Körber European Science Prize.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.